LOTUS/SLURM issues update 2
Last modified on February 25, 2025 • 4 min read • 745 wordsIn the past month, and following the configuration changes to LOTUS over the summer, we have not been able to fully resolve issues around longer queue wait times, despite the mechanisms outlined here.
While the changes we advertised then were successful in dealing with the known problems, there have been continuing reports of ongoing difficulties. We continue to work on these, but many of them are simply down to load: during this year the LOTUS load has grown so there are more big users and longer wait times. Disentangling problems which arise from load and those which arise from configuration has been, and continues to be, difficult.
We now believe that we will have to make some rather major changes to the LOTUS environment. This update covers what we have done, what we plan to do in the near future, and outlines some of the necessary changes ahead. At the end of this sequence of changes we are aiming to improve response time (i.e. deliver shorter queue waits) for the bulk of users, while giving more predictability to the larger users. Unfortunately, giving more predictability will likely involve more workflow scheduling by those large users (less relying on the LOTUS batch scheduler) and an allocation mechanism to limit usage. Exactly how we achieve that is under discussion and will need to be ratified by the CEDA/JASMIN Board before deployment. However, there are many things we can do in the meanwhile to improve things for most users.
What have we done?
- As is obvious, we have completed the transition from the LSF to the SLURM scheduler. This was an unavoidable change; the good news is that the volume of work (in core hours) has been sustained throughout the transition, and in fact now exceeds that which was being done prior to the transition:
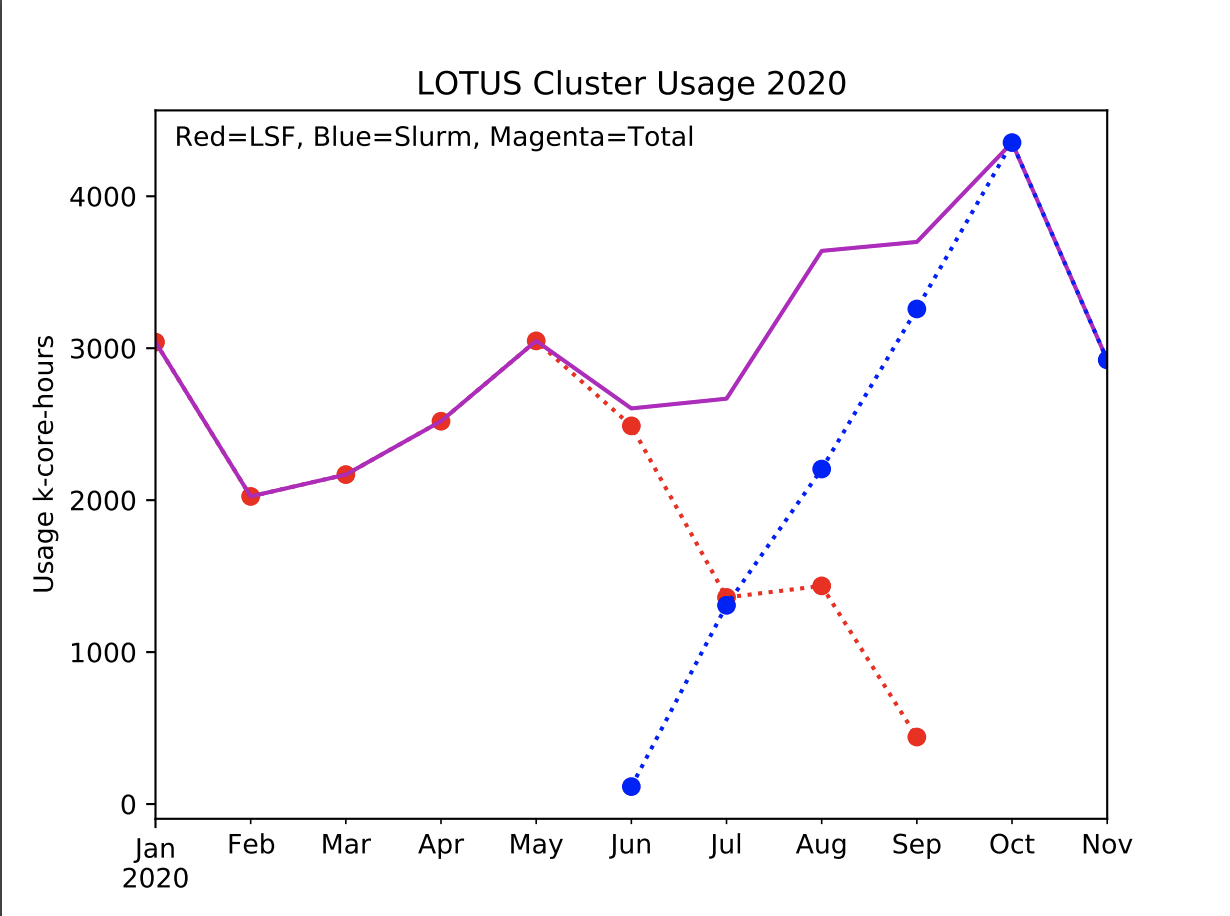
- The increase in workload was possible because more compute nodes have been added to LOTUS and distributed into the various queues.
- A new queue with dedicated compute nodes has been temporarily (see below) added for short serial jobs with a maximum run time limit of 4 hours - “short-serial-4hr”.
- We continue to modify the way that jobs are prioritised (the “fairshare” algorithm). Since the last announcement we have made changes to increase the priority of smaller jobs in all queues and to further decrease the priority of those who have recently used a lot of resources.
- Some additional community queues have been temporarily (see below) established to support some of the more time-orientated operational activities.
What do we plan to do in the near future?
- We are monitoring LOTUS usage (including wait times per queue) on a weekly basis, and will continue to tweak the fairshare algorithm over time.
- We will reconfigure the limits which apply to jobs to make it easier for the scheduler to do prioritisation.
- We will restructure the SLURM queues (“partitions”) to better separate workflows, and in doing so limit the number of jobs any one user can have scheduled at any one time in some queues, and ensure those queues have priority.
- In practice this means all the existing queues can be considered as “temporary” until such time as we announce and deploy the new queue structure.
In the mid-term we expect to:
- 1st Quarter 2021: Develop policy and mechanisms for dividing the workload between “large allocations” and “daily on-demand analysis”, with the former delivered via a fast, responsive, lightweight allocations procedure based on funding source and consortium-wide allocations.
- 2nd Quarter 2021: Add more hardware to the LOTUS queues.
Future announcements will give details and warning of all the fundamental changes (i.e. which go beyond tweaking the fairshare algorithm).
How can you help us?
- Those communities who have predictable large demands and the financial resources to buy into dedicated queues (with dedicated hardware) should discuss their requirements with the JASMIN team so we can give you reliable service without impacting the general users.
- We continue to value feedback, and in particular feedback which gives us enough information to understand your requirements and how the system response to those requirements has changed (particularly changes since October and in response to changes we might make after today).
- Recognise that as we make changes, it will sometimes take weeks to see how those changes have manifested for the average workload (since of course, on a week by week basis, nothing you do is average - in any sense).
Thank you for your patience and cooperation.
JASMIN team